TCP 是 TCP/IP 协议簇中重要的一员,它为通信双端提供有连接的、可靠的传输服务。
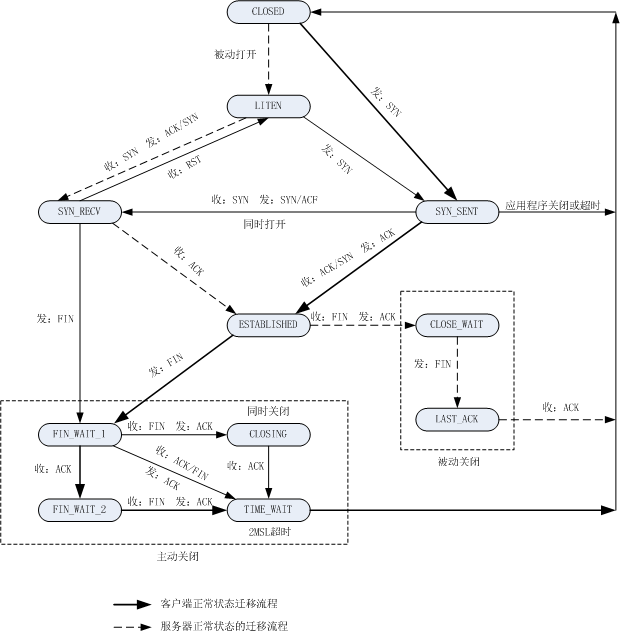
TCP 状态迁移
TCP 交互数据流
如果按照分组数量计算,约有一半的 TCP 报文段包含成块数据(如FTP、电子邮件和Usenet新闻), 另一半则包含交互数据(如Telnet和Rlogin)。 如果按字节计算,则成块数据与交互数据的比例约为 90% 和 10%。 这是因为成块数据的报文段长度基本上都是满长度,而交互数据则小得多。
TCP 需要同时处理这两类数据,但使用的处理算法则有所不同。 对于交互数据,TCP 主要使用 延时确认 和 Nagle算法 减少网络上的 TCP 小分组数量; 而对于成块数据,则主要使用 滑动窗口协议 和 慢启动算法 来控制流量,避免拥塞。
经受时延的确认
通常 TCP 在接收到数据时并不立即发送 ACK,相反,它推迟发送, 以便将 ACK 与需要沿该方向发送的数据一起发送(有时称这种现象为数据捎带 ACK)。 绝大多数实现采用的时延为 200ms,也就是说,TCP 将以最大 200ms 的时延等待是否有数据一起发送。
Nagle 算法
Nagle 算法要求一个 TCP 连接上最多只能有一个未被确认的未完成的小分组,在该分组的确认到达之前不能发送其他的小分组。 这些等待发送的小分组将被 TCP 收集,并在确认到来之时组装成一个分组发送出去。 该算法的优越之处在于它是自适应的:确认到达得越快,数据也就发送得越快。 而在希望减少小分组数目的低速广域网上,则会发送更少的分组。
Nagle 算法有效的提高了广域网带宽的利用率,但对用户体验而言,它并不友善。 所以,有时我们需要关闭 Nagle 算法。一个典型的例子是 X窗口系统服务器: 小消息(鼠标移动)必须无时延的发送,以便为进行某种操作的交互用户提供实时的反馈。
使用 Berkeley Socket API 的用户可通过 TCP_NODELAY 选项来关闭 Nagle 算法。
TCP成块数据流
滑动窗口
在 TCP 首部字段中有个 16 字节的 win 字段,它又被称为通告窗口,用于通告本端接收缓冲区的可用大小。 对于发送方而言,它所发送到连接上的未经确认的分组字节不能超过对端通告的窗口大小。
在一个活跃的 TCP 连接上,通告窗口是动态变化的,我们用三个术语描述窗口左右边沿的运动:
- 窗口左边沿向右边靠近称为 窗口合拢 。这种现象发生在接收方收到数据时。
- 窗口右边沿向右移动称为 窗口张开 。这种现象发生在接收方应用进程从 TCP 接收缓冲区取出数据时。
- 当右边沿向左边移动时,我们称之为 窗口收缩 。Host Requirements RFC 强烈建议不要使用这种方式。 但 TCP 必须能够在某一端产生这种情况时进行处理。
慢启动算法
慢启动算法协调新分组进入网络的速率与另一端返回确认的速率。
慢启动算法为发送方的 TCP 增加了另一个窗口:拥塞窗口(congestion window),记为 cwnd。 当与另一个网络的主机建立 TCP 连接时,拥塞窗口被初始化为 1 个报文段(即另一端通告的报文段大小:mss)。 每收到一个 ACK,拥塞窗口就增加一个报文段(cwnd以字节为单位,但是慢启动以报文段大小为单位进行增加)。 发送方取拥塞窗口与通告窗口中的最小字节作为发送上限。 拥塞窗口是发送方使用的流量控制,而通告窗口则是接收方使用的流量控制。
发送方开始时发送一个报文段,然后等待 ACK。 当收到该 ACK 时,拥塞窗口从 1 增加到 2,即可以发送两个报文段。 当收到这两个报文段的 ACK 时,拥塞窗口就增加为 4。这是一种指数式增长。
TCP的超时和重传机制
TCP 定时器
对于每个 TCP 连接,TCP 管理 4 个不同的定时器:
-
重传定时器
当发送一个报文段时:若该定时器处于关闭状态,则该会启动一个针对该报文的定时器; 当对端确认该报文后,关闭该定时器。
-
坚持定时器(persist)
当接收方关闭其窗口时,发送方将启动该定时器定时探测接收方窗口信息。
-
保活定时器(keep alive)
用于检测一个空闲连接的另一方何时崩溃或重启。
-
2MSL定时器
在连接的一方执行主动关闭进入 TIME_WAIT 状态时,将启动该定时器; 以防本端发送的最后一个 ACK 丢失,收到对端 FIN 时再次发送 ACK
重传间隔
最初的超时重传间隔时间计算
名词解释
- R: RTT(Round-Trip Time)
- M: 最近一次测量到的 RTT
- alpha: 插值因子,取值为 0.9
- beta: 推荐值为 2 的时延离散因子
- RTO: 重传超时时间(Retransmission Timeout)
重传间隔计算
R = alpha*R + (1-alpha)*M 每次测量到新的 RTT 即 M 时,R 的值将被更新, 这个新的估计值 90% 来自前一个估计, 10% 则取自新的测量。
最初使用的超时重传间隔: RTO = beta*R 。 [Jacobson 1988] 详细分析了在 RTT 变化范围很大时,使用这个方法无法跟上这种变化,从而引起不必要的重传。 正如 Jacobson 所描述的那样,当网络已处于饱和状态时,不必要的重传会增加网络的负载,对网络而言这就像火上浇油一样。
新的超时重传间隔计算算法
名词解释
- A: 被平滑的 RTT
- M: 最近一次测量到的 RTT
- Err: M-A
- D: 被平滑的均值偏差
- RTO: 重传超时时间
- g: 取值0.125
- h: 偏差增益,取值0.25
重传间隔计算
- Err = M - A
- A = A + gErr
- D = D + h(|Err|-D)
- RTO = A + 4D
拥塞避免算法
拥塞避免算法是一种处理丢失分组的方法。 该算法假定由于分组受到损坏引起的丢失是非常少的,因此分组丢失就意味着在源主机和目的主机之间的某处网络上发生了拥塞。 有两种分组丢失的指示:发生超时和收到重复的确认。
拥塞避免算法和慢启动算法是两个目的不同的、独立的算法。但是当拥塞发生时, 我们希望降低分组进入网络的传输速率,于是可以调用慢启动来做到这一点。 在实际中这两个算法通常一起实现。
拥塞避免算法和慢启动算法需要对每个连接维持两个变量:一个拥塞窗口变量(cwnd)和一个慢启动门限(ssthresh)。 算法流程如下:
-
对一个给定的连接,初始化 cwnd 为 1 个报文段, ssthresh 为 65535 个字节。
-
TCP 输出例程的输出不能超过 cwnd 和接收方通告窗口的大小。 拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。 前者是发送方感受到网络拥塞的估计,而后者则与接收方在该连接上的可用缓存大小有关。
-
当拥塞发生时(超时或收到重复确认), ssthresh 被设置为当前窗口大小的一半(cwnd 和接收方通告窗口大小的最小值,但最少为 2 个报文段)。 此外,如果是超时引起了拥塞,则 cwnd 被设置为 1 个报文段(慢启动的初始值)。
-
当新的数据被对方确认时,就增加 cwnd,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免。 如果 cwnd <= ssthresh,则正在进行慢启动,否则正在进行拥塞避免。 慢启动算法初始时设置 cwnd 为一个报文段,此后每收到一个确认就加 1; 拥塞避免算法要求每次收到一个确认时将 cwnd 增加 1/cwnd。 与慢启动的指数式增长比起来,这是一种 additive increase。 我们希望在一个往返时间内最多为 cwnd 增加 1 个报文段,而慢启动将根据这个往返时间中所收到的确认的个数增加 cwnd。
快速重传和快速恢复算法
在 TCP 的一端收到一个失序的报文段时,TCP 需要立即产生一个重复的 ACK,这个重复的 ACK 不应该被延迟, 该重复的 ACK 的目的在于告诉对端我们收到一个失序的报文段,希望对端重传。
由于我们不知道一个重复的 ACK 是由一个丢失的报文段引起的,还是由于仅仅出现了几个报文段的重新排序,因此我们等待少量重复的 ACK 到来。 假如这只是一些报文段的重新排序,则在重新排序的报文段被处理并产生一个新的 ACK 之前, 只可能产生 1~2 个重复的 ACK。如果一连收到 3 个或 3 个以上的重复的 ACK,就非常可能是一个报文段丢失了。 于是,我们就重传丢失的数据报文段,而无需等待超时定时器溢出,这就是快速重传算法。 接下来执行的不是慢启动算法而是拥塞避免算法,这就是快速恢复算法。
快速重传和快速恢复算法的执行流程如下:
-
当收到第 3 个重复的 ACK 时,执行:ssthresh = cwnd/2; cwnd = ssthresh+3mss; 并重传丢失的分组。
-
每次收到另一个重复的 ACK 时,cwnd 增加 1 个报文段大小并发送 1 个分组(如果新的 cwnd 允许发送)。
-
当下一个确认新数据的 ACK 到达时,设置 cwnd 为 ssthresh (在第 1 步中设置的值)。 这个 ACK 应该是在进行重传后的一个往返时间内对步骤 1 中重传的确认。 另外,这个 ACK 也应该是对丢失的分组和收到的第 1 个重复的 ACK 之间的所有中间报文段的确认。 这一步采用的是拥塞避免,因为当分组丢失时我们将当前的速率减半。
ICMP 差错
一个接收到的主机不可达或网络不可达差错实际上都被忽略,因为这两个差错都被认为是短暂现象。 这有可能是由于中间路由器被关闭而导致选路协议要花费数分钟才能稳定地切换到另一个替换路由。 在这个过程中就可能发生这两个 ICMP 差错中的一个,但是 TCP 连接并不被关闭。 相反,TCP 试图发送引起该差错的数据,尽管最终有可能会超时。 当前基于 Berkeley 的实现记录发生的 ICMP 差错,如果连接超时,ICMP 差错被转换为一个更合适的差错码而不是“连接超时”
TCP 坚持定时器
TCP 坚持定时器存在的意义
TCP 通过让接收方指明希望从发送方接收的数据字节数(即窗口大小)来进行流量控制。 如果窗口大小为 0 会发生什么情况呢?这将有效地阻止发送方传送数据,直达窗口变为非 0 为止。 当接收方通告窗口为 0 时,发送方不再向接收方发送数据,当接收方窗口张开时,接收方需要通过 ACK 分组告知发送方新的窗口大小。 但 TCP 不对 ACK 报文进行确认,TCP 只确认那些包含数据的 ACK 报文段。 如果一个确认丢失了,则双方就有可能因为等待对方而使连接超时终止。 为防止这种死锁现象发生,发送方使用坚持定时器来周期性地向对方查询,以便发现窗口是否已增大。 这些从发送发出的报文段称为窗口探查(window probe)。
糊涂窗口综合症
窗口探查报文总是包含 1 字节的数据,周期性的发送此报文可能导致少量数据通过连接进行交换。 此即糊涂窗口综合症。该现象可发生在两端中的任何一端: 接收方可以通告一个小的窗口(而不是一直等到有大的窗口时才通告); 而发送方也可以发送少量的数据(而不是等待其他数据以便发送一个大的报文段)。 可以在任何一端采取措施避免出现糊涂窗口综合症的现象:
-
接收方不通告小窗口。 通常的算法是接收方不通告一个比当前窗口大的窗口(可以为0), 除非窗口可以增加一个报文段大小(也就是对端的 mss)或者可以增加接收缓存的一半(不论实际有多少)。
-
发送方避免糊涂窗口综合症的措施是只在下列条件至少满足一条时才发送数据: a) 可以发送一个满长度的报文段 b) 可以发送接收方初始接收缓存的一半大小的数据